We're in the last week of classes, lectures are now done for this class and we are all starting to study.
So what have I learned? Well, the interesting thing about this class, is that week to week I felt like I wasn't really learning anything new. Recursion was an idea that I had seen before, and it seemed like we were just drilling that into our heads week after week. It seemed like we were learning one idea over and over for the whole class.
Although looking back, I know WAYYYY more than I did since class started. My programming alone is significantly more efficient and I am able to pull apart problems in a much more systematic way now. It's interesting that you can be unaware that you are learning, but learn so much.
With this course, I bid goodbye to computer science, as I will be starting programs in mathematics and actuarial science. I really did enjoy it though, and this was by far my most interesting class this year.
Thursday, April 3, 2014
Monday, March 31, 2014
On the midterm exam, aka. something that needs to be said.
My mom is bad at math. I have tried many times to show her things that I think are really cool little tidbits of mathematics, and even things that are relatively simple she has trouble grasping. However my mom is an incredibly intelligent woman who has 3 degrees and graduated with a 4.0 GPA from Mt. Allison University in 1981.
Does not being bad at math make my mom stupid? By most people's standards, absolutely not. She is just not cut out for Math, and that is perfectly fine.
So this last midterm had a raw average of about 44%, which is the worst I have seen in any of my classes so far at U of T. Most of the people I know who are relatively talented at computer science or math easily got over 100% (one such friend got 100% BEFORE curving), so I have one thing to say:
Maybe if you failed, computer science isn't for you.
Sure, you may want it to be, you may like video games and want to program them, perhaps you heard that computer science can lead to a lucrative career. However if you struggle so badly to do something that a significant amount of people can do well at... maybe it isn't for you and you should consider something more in line with your talents.
Does not being bad at math make my mom stupid? By most people's standards, absolutely not. She is just not cut out for Math, and that is perfectly fine.
So this last midterm had a raw average of about 44%, which is the worst I have seen in any of my classes so far at U of T. Most of the people I know who are relatively talented at computer science or math easily got over 100% (one such friend got 100% BEFORE curving), so I have one thing to say:
Maybe if you failed, computer science isn't for you.
Sure, you may want it to be, you may like video games and want to program them, perhaps you heard that computer science can lead to a lucrative career. However if you struggle so badly to do something that a significant amount of people can do well at... maybe it isn't for you and you should consider something more in line with your talents.
Sunday, March 30, 2014
Addendum on Efficiency.
So I did it. I decided to explain Big O notation to my 77 Year old Grandmother (she had a birthday earlier this month!). It was I think somewhat successful, but here was what I said:
Unfortunately though I couldn't think of a proper way to explain more complex algorithms in terms of onions.
Alright, so we recently learned this thing in class called Big O notation, which we use to give a rough estimate of how good, or god awful a function we wrote is. So imagine, you are cooking dinner and you have two ways you could chop an onion. One is to chop it in 10 slices horizontally, 10 vertically, and 10 lengthwise. No matter what, this will take you 30 slices, which is constant no matter what the size of the onion, so we would say that the expected time that this algorithm takes is ALWAYS 30, or O(1), the 1 just stands for constant. Now contrast this to an algorithm that takes an onion, and cuts it into .5 cm pieces. Well, a 6 cm diameter onion would have the same expected time, but if it was 7 cm, all of a sudden we have 36 cuts to do, 8 cm would take us 42 etc, so now we have something that grows depending on the onion. If we carefully look at how this grows, we see that for every 1 cm of extra onion, you do 6 extra cuts, so we notate that as O(n) where the one stands for "grows with n".
Unfortunately though I couldn't think of a proper way to explain more complex algorithms in terms of onions.
Sunday, March 23, 2014
Making tasks super inefficient.
So, we have to write about efficiency. Well, instead of doing what most people are doing, which is likely explaining what it is etc., my goal in this blog is to take a bunch of familiar concepts in programming, and write the most inefficient code I can think of in order to demonstrate some key ideas.
First though, I feel obliged to give the coles notes version of the notation we will be using in this discussion, "Big O" notation. We can pretend it's some kind of magic mathematical voodoo, or we can just think of it like I do, Lazy man equations.
What do I mean by lazy man equations? Well imagine you are someone who wants to use an equation to describe how well something he made works, but he hates actually sitting down and formulating a precise equation. So the lazy man says "well, it's pretty close to this" and that's what we get. For example, let's say the precise equation for something is that it takes n(n+1)/2 operations for some n. Well, we would say "it's pretty close to n^2" so we say it is O(n^2). Or perhaps it is e^n+n^99, eventually e^n will be the biggest, and we don't really care that the base number is e since we are lazy, so we just say it is O(a^n).
So let's get to the meat of this post shall we?
Big O
First though, I feel obliged to give the coles notes version of the notation we will be using in this discussion, "Big O" notation. We can pretend it's some kind of magic mathematical voodoo, or we can just think of it like I do, Lazy man equations.
What do I mean by lazy man equations? Well imagine you are someone who wants to use an equation to describe how well something he made works, but he hates actually sitting down and formulating a precise equation. So the lazy man says "well, it's pretty close to this" and that's what we get. For example, let's say the precise equation for something is that it takes n(n+1)/2 operations for some n. Well, we would say "it's pretty close to n^2" so we say it is O(n^2). Or perhaps it is e^n+n^99, eventually e^n will be the biggest, and we don't really care that the base number is e since we are lazy, so we just say it is O(a^n).
So let's get to the meat of this post shall we?
Crappy Sorting
So how could we sort really poorly?
Let's imagine we have a list with items in it, for example [4, 1, 3, 2].
I can think of one insanely bad way. How about we check if it is sorted... and then we randomize the list and check if it is sorted again?
[4, 1, 3, 2] not sorted! go again!
[4, 3, 2, 1] not sorted! (wrong order) go again!
etc.
So how can we describe this in our lazy man notation?
Well the fastest it could work is one iteration, so the best case we would describe as O(1). The average it would work, is about O(n!) which is pretty bad.
But oh, what about the worst case???? Well it is within the realm of possibility that it may never work, so we would actually say O(∞).
Truly a terrible algorithm.
Let's imagine we have a list with items in it, for example [4, 1, 3, 2].
I can think of one insanely bad way. How about we check if it is sorted... and then we randomize the list and check if it is sorted again?
[4, 1, 3, 2] not sorted! go again!
[4, 3, 2, 1] not sorted! (wrong order) go again!
etc.
So how can we describe this in our lazy man notation?
Well the fastest it could work is one iteration, so the best case we would describe as O(1). The average it would work, is about O(n!) which is pretty bad.
But oh, what about the worst case???? Well it is within the realm of possibility that it may never work, so we would actually say O(∞).
Truly a terrible algorithm.
Crappy Prime Number Checker.
Let's say we want to find if a number is prime. Well the first way you would imagine is to just check if every number before it divides into it. The way a computer would probably do this is with modulo, so we can think of it integer dividing + 1 each number p n//p +1 times. So for every p up to n this roughly works out to n + n/2 + n/3 + n/4 ... + n/n etc, which would be approximately O(n^2).
This is pretty crappy, since we can actually eliminate a whole bunch of numbers simply by realizing that we only need to check up to sqrt(n). Which actually means that our algorithm is n/2 + n/3 + n/4 ... + n/sqrt(n) however this is STILL O(n^2), although some might say that it is "subquadratic" but that is another topic for another day.
And for a change of pace... the world's most efficient sorting algorithm.
This is pretty crappy, since we can actually eliminate a whole bunch of numbers simply by realizing that we only need to check up to sqrt(n). Which actually means that our algorithm is n/2 + n/3 + n/4 ... + n/sqrt(n) however this is STILL O(n^2), although some might say that it is "subquadratic" but that is another topic for another day.
And for a change of pace... the world's most efficient sorting algorithm.
(courtesy of StackOverflow):
Presenting Intelligent Design Sort:
Introduction
Intelligent design sort is a sorting algorithm based on the theory of intelligent design.
Algorithm Description
The probability of the original input list being in the exact order it's in is 1/(n!). There is such a small likelihood of this that it's clearly absurd to say that this happened by chance, so it must have been consciously put in that order by an intelligent Sorter. Therefore it's safe to assume that it's already optimally Sorted in some way that transcends our naïve mortal understanding of "ascending order". Any attempt to change that order to conform to our own preconceptions would actually make it less sorted.
Analysis
This algorithm is constant in time, and sorts the list in-place, requiring no additional memory at all. In fact, it doesn't even require any of that suspicious technological computer stuff. Praise the Sorter!
Feedback
Gary Rogers writes:
Making the sort constant in time denies the power of The Sorter. The Sorter exists outside of time, thus the sort is timeless. To require time to validate the sort dimishes the role of the Sorter. Thus... this particular sort is flawed, and can not be attributed to 'The Sorter'.
Heresy!
Making the sort constant in time denies the power of The Sorter. The Sorter exists outside of time, thus the sort is timeless. To require time to validate the sort dimishes the role of the Sorter. Thus... this particular sort is flawed, and can not be attributed to 'The Sorter'.
Thursday, March 20, 2014
Chess. (Part II)
So let's talk about strategy.
What is strategy exactly? Well I have always thought about it as a set of imposed rules that are beneficial towards some goal. For example when someone plays poker, they may have a set of "rules" they tell themselves like "never bet your life savings on a bad hand" which are not explicitly part of the rules of the game.
Now as I have said many times, computers are idiots, you need to spell out EVERYTHING to them. So how can we teach them a proper strategy?
Well the answer is to take into account EVERY contingency.
Now to apply this to chess. Take a look at this board:

So the key is teaching the computer some kind of point system to evaluate the moves. One of the ways this is done is to think of various pieces as having point values:
pawn - 1
bishop and knight - 3
rooks - 5
queen - 9
king - over 9000
So while the computer is checking possible move permutations, it might get black to try and capture the knight if you played b6, but then as white you would be able to capture the king and thus get 9000 points. Also as it tests various lines, it would stumble upon checkmate in this way since it would find an unavoidable line that results in the king being captured.
Sunday, March 9, 2014
Recursing upwards.
It was pointed out to me that usually when we do recursive things it heads downwards, until we hit a value of 1 or 0.
So I tried to come up with an example of something that would "recurse upwards" so to speak.
Let's say we want to create a list of lottery numbers, well we could use this kind of upward recursion to populate and return a list of however many numbers we want, like this:
So I tried to come up with an example of something that would "recurse upwards" so to speak.
Let's say we want to create a list of lottery numbers, well we could use this kind of upward recursion to populate and return a list of however many numbers we want, like this:
from random import randint
def lottery(start: int=1, end: int=49, amount: int=6, numbers: list=None):
if not numbers:
numbers = []
chosen = False
while not chosen:
number = randint(start, end)
if not number in numbers:
chosen = True
numbers.append(number)
if len(numbers) < amount:
lottery(start=start, end=end, amount=amount, numbers=numbers)
else:
numbers.sort()
return numbers
return numbers
Of course we could do the same thing without recursion, but it's always interesting to experiment!
Of course we could do the same thing without recursion, but it's always interesting to experiment!
Wednesday, March 5, 2014
Chess. (Part I)
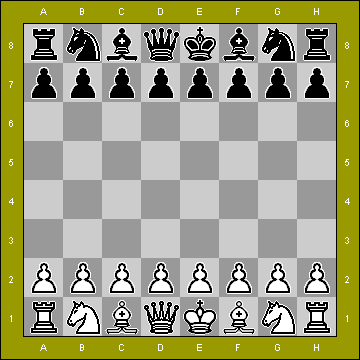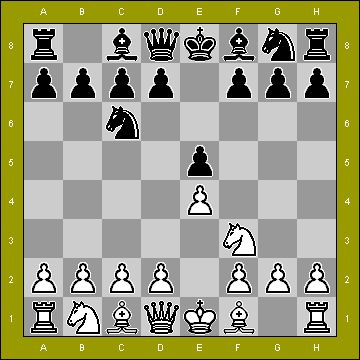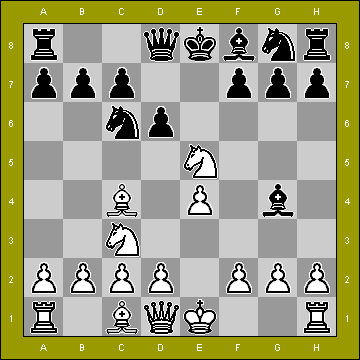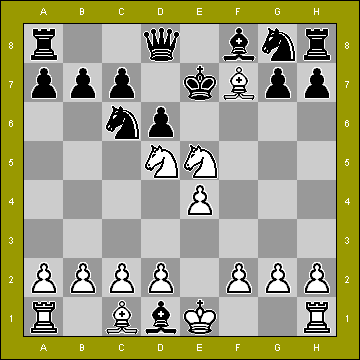
Chess engines.
For the unaware, a chess engine is a computer program specifically written to play chess. It makes a good problem since currently chess is an unsolved game (i.e there is no known strategy that will win every time), but it can quite easily be represented and evaluated in computer memory if done right.
So how might we write one? Well the first thing to think of are the basic classes we might want to simplify things. Some immediate ideas that spring to mind are:
1. A representation of the current state of the board, with a specific place for each piece, and when a move is executed it updates the board.
2. Each piece with it's legal moves.
Programming the piece movements is actually a fairly complicated question, for a few reasons. Some pieces are simple, for example the Knight. Let's say we represented co-ordinates on the board as (7,1) for G1, or C6 as (3,2) then we might make a list of legal Knight moves by creating a list of tuples where we add all 8 possible move permutations:
1. right 2, down 1 (2, -1)
2. right 2, up 1 (2, 1)
3. right 1 down 2 (1, -2)
4. right 1, up 2 (1, 2)
5. left 2, down 1 (-2, -1)
6. left 2, up 1 (-2, 1)
7. left 1 down 2 (-1, -2)
8. left 1, up 2 (-1, 2)
So for example, if we ran our function on G1, we would have the list:
[(9, 0), (9, 2), (8, -1), (8, 3), (5, 0), (5, 2), (6, -1), (6, 3)]
Then we would need to filter our list, since our coordinates are only from 1 to 8 inclusive, so we would have:
[(8, 3), (5, 2), (6, 3)]
We would then just have to exclude moves that are already occupied by our pieces, for example on the opening we couldn't play E2 since it is occupied by a pawn, so our move list would be [(8,3), (6,3)].
Other pieces get way more complicated, for example with rooks we would have to take castling into account, whether we can capture, all possible moves in each rank and file, etc
When we also think about board positions, we need to take all the possible moves, and then somehow evaluate them. This will be the topic of part II.
Sunday, February 23, 2014
We must go deeper!

Well there are 2 (kind of similar) answers, one is how I and many others think of it, and one is the official understanding of what it is.
First the official version, mainly so we can forget about it and move on immediately after. According to Miriam Webster, recursion is:
The determination of a succession of elements (as numbers of functions) by operation on one or more preceding elements according to a rule or formula involving a finite number of steps.Huh?
Well, let's look at some examples and come to an understanding of what it is ourselves.
The first example I was exposed to, waaaaaaaaay before starting this course is my old friend the factorial. In math, a factorial is essentially a number multiplied by all the successive numbers between itself and 1. For example: 7! = 7x6x5x4x3x2x1, 4! = 4x3x2x1 etc. Factorials are incredibly useful in probability since they represent the amount of ways you can arrange a group of objects.
So how would this look in python?
Well, one way is like this:
def factorial(n):
total = n
for num in range(1,n):
total *= num
return total
Which certainly works (and one might argue would be a little easier on the ol' computer memory) but we can write a "simpler" *cough* version using recursion. Here's how it would look:
def factorial(n):
if n == 1:
return 1
else:
return n*factorial(n-1)
So here is the big breakthrough here, we can write functions that call THEMSELVES, which is what recursion is. Factorial is perhaps a bad example, because you might be asking me "Well, why would we bother hurting our brain trying to write that when I can just write the other version that is easier for me to understand?" To which I would reply "so you can be lazy later".
Here is what I mean.
Let's say we have a list of numbers and we want to sort them, and we want to sort them as fast as we possibly can (not exactly but we can pretend for sake of example). We want to use a magical type of sorting called quick sort! But what is quick sort?
Imagine we have a list of items: [1,6,3,4,2,5] and we want to sort them fast, first we will choose a random number called a "pivot", in this case we will choose 3. Then what we do is we make 2 more lists, one that has numbers less than 3, and one that has numbers greater than 3, which in this case would yield:
pivot = [3]
less = [1,2]
more = [6,4,5]
Then we do the same thing to less, and more. So for less we might choose 1 as the pivot, so only 2 gets put into more and nothing gets put into less, and for more if we choose 5, 4 gets put into less etc. Then when it is all done we put it together, so we would have something like:
less' less = []
less' pivot = [1]
less' more = [2]
Added up becomes [1,2] and:
more's less = [4]
more's pivot = [5]
more's more = [6]
Added up becomes [4,5,6]
So then we have, originally:
less = [1,2]
pivot = [3]
more = [4,5,6]
And added up is [1,2,3,4,5,6], our sorted list!
Written in non-recursive code this is a bit of a nightmare, as you would have to have a bunch of variables to account for all possible permutations of the six items so that we can quick sort them with a bunch of nested if and else statements. Then if we passed a list with 7 items, suddenly it wouldn't work consistently anymore, and we would have to add more nested if and else statements.
Talk about a lot of work! Luckily for us we can be lazy bums and write this recursively and save ourselves the time. Here's how that would look.
def quicksort(list):
if len(list) <= 1:
return list
else:
pivot = [list[0]]
more = []
less = []
for number in list[1:]:
if number >= pivot[0]:
more.append(number)
else:
less.append(number)
return quicksort(less) + pivot + quicksort(more)
Which is actually pretty simple! All it requires is calling our function for the smaller lists until we end up with a list of one/no items, which is already sorted for us :-).
Thursday, February 20, 2014
Project Euler
What is the easiest way to study for a programming exam?
Program. It's as simple as that! So after finishing up assignment 2 part 1 (which seems unsettlingly easy) I decided to dive into some programming problems in order to practice some of the concepts I will need to know for the test. These problems are courtesy of a website called Project Euler, which is essentially a huge database of math problems that (mostly) require a computer to solve.
Problem 1, Square Root Convergents:
So what I did was I made a Fraction class, which has two attributes: a numerator, and a denominator. Then I noticed that for every iteration, we add 1 to the entire thing, put it as the denominator of a fraction (which convieniently is a reciprocal, and then just add 1 again. As an example, if we have our first iteration, which is 3/2 and we add 1 to it we get 5/2, the reciprocal of that is 2/5, and then 1 added to that is 7/5 which is our second iteration. Then we do it again, add 1 to get 12/5, reciprocal is 5/12, add 1 to get 17/12 which is our third iteration. So all I did was make a new fraction by adding the denominator to the numerator, switching the variables, and then adding the denominator in the new fraction to the numerator.
Then all that was needed was to make a simple list comprehension that did all of these fraction expansions and reduced them on every successive iteration. Followed by a filtering of the list by reading the length of the numerator.
This gives the final answer of 153.
Problem 2, Multiples of 3 and 5:
The natural thought process is that to solve it we must iterate through all the numbers from 1 to 999, take out the ones that are multiples of 3 or 5, and then sum all of these together. The way I originally solved it was with an accumulator, and the code looked something like this:
total = 0
for num in range(1, 1000):
if num%3 == 0 or num%5 == 0:
total += num
print(num)
So how could we do this in one line? Well with list comprehensions of course! To get a list with all of the numbers that have this property, we can write it like this:
[num for num in range(1, 1000) if num%3 == 0 or num%5 ==0]
So all we need to do is sum them up, and print them, which gives us the one-line beauty:
print(sum([num for num in range(1, 1000) if num%3 == 0 or num%5 ==0]))
Which gives us the final answer of 233168.
Problem 3, Largest Prime Factor:
Every number can be divided into prime factors, for example 10 can be written as 2x5. The natural thing to do would be to iterate over the prime numbers, and if they divided our number, we divide our number by that, and add that factor to the list. We would then stop iterating when we get to a number that is higher than the number ours has become, and the number we are left over with is in fact the largest prime factor.
Now the truth is, with this implementation, we CANNOT write it in one line, since it requires a variable to be set to 600851475143 for us mess with among other factors. However we can actually write a one line program for this, (although it may not fit on one line on this blog):
print(max([factor for factor in range(2, 600851475143) if (600851475143%factor==0 and len([n for n in range(2, factor) if factor%n == 0]) == 0)]))
What it is basically doing is populating a list of numbers that divide 600851475143 evenly, and which cannot be divided evenly by any number other than 1 and itself (i.e. the list of numbers that divide this number between 2 and itself-1 has a length of 0). After that it simply prints out the largest number in that list, which is by definition our "largest prime factor".
The thing is though, this is a HORRIBLE program, and would take a long time to run even on a supercomputer (In fact, trying it myself it generates a memory error before it gets anywhere). So there is a lesson here, SOMETIMES ONE LINE PROGRAMS ARE NOT THE BEST PROGRAMS.
Anyways, implementing the originally stated algorithm, I got the correct answer of 6857 in a much, much faster time, less than a second.
Program. It's as simple as that! So after finishing up assignment 2 part 1 (which seems unsettlingly easy) I decided to dive into some programming problems in order to practice some of the concepts I will need to know for the test. These problems are courtesy of a website called Project Euler, which is essentially a huge database of math problems that (mostly) require a computer to solve.
Problem 1, Square Root Convergents:
It is possible to show that the square root of two can be expressed as an infinite continued fraction.So to solve this I need to have some way to keep track of numerators and denominators, to reduce successive fractions, to check if the numerator has more digits than the denominator, and to find the next iteration of the continued fraction expansion.
2 = 1 + 1/(2 + 1/(2 + 1/(2 + ... ))) = 1.414213...
By expanding this for the first four iterations, we get:
1 + 1/2 = 3/2 = 1.5
1 + 1/(2 + 1/2) = 7/5 = 1.4
1 + 1/(2 + 1/(2 + 1/2)) = 17/12 = 1.41666...
1 + 1/(2 + 1/(2 + 1/(2 + 1/2))) = 41/29 = 1.41379...
The next three expansions are 99/70, 239/169, and 577/408, but the eighth expansion, 1393/985, is the first example where the number of digits in the numerator exceeds the number of digits in the denominator.
In the first one-thousand expansions, how many fractions contain a numerator with more digits than denominator?
So what I did was I made a Fraction class, which has two attributes: a numerator, and a denominator. Then I noticed that for every iteration, we add 1 to the entire thing, put it as the denominator of a fraction (which convieniently is a reciprocal, and then just add 1 again. As an example, if we have our first iteration, which is 3/2 and we add 1 to it we get 5/2, the reciprocal of that is 2/5, and then 1 added to that is 7/5 which is our second iteration. Then we do it again, add 1 to get 12/5, reciprocal is 5/12, add 1 to get 17/12 which is our third iteration. So all I did was make a new fraction by adding the denominator to the numerator, switching the variables, and then adding the denominator in the new fraction to the numerator.
Then all that was needed was to make a simple list comprehension that did all of these fraction expansions and reduced them on every successive iteration. Followed by a filtering of the list by reading the length of the numerator.
This gives the final answer of 153.
Problem 2, Multiples of 3 and 5:
If we list all the natural numbers below 10 that are multiples of 3 or 5, we get 3, 5, 6 and 9. The sum of these multiples is 23.This is the very first problem on the site, which is incredibly easy to solve however in order to practice the concepts, it makes for a good problem since you can write it in one line.
Find the sum of all the multiples of 3 or 5 below 1000.
The natural thought process is that to solve it we must iterate through all the numbers from 1 to 999, take out the ones that are multiples of 3 or 5, and then sum all of these together. The way I originally solved it was with an accumulator, and the code looked something like this:
total = 0
for num in range(1, 1000):
if num%3 == 0 or num%5 == 0:
total += num
print(num)
So how could we do this in one line? Well with list comprehensions of course! To get a list with all of the numbers that have this property, we can write it like this:
[num for num in range(1, 1000) if num%3 == 0 or num%5 ==0]
So all we need to do is sum them up, and print them, which gives us the one-line beauty:
print(sum([num for num in range(1, 1000) if num%3 == 0 or num%5 ==0]))
Which gives us the final answer of 233168.
Problem 3, Largest Prime Factor:
So, can this one be written in one line? Let's first think of what we can do to solve this.
The prime factors of 13195 are 5, 7, 13 and 29.
What is the largest prime factor of the number 600851475143 ?
Every number can be divided into prime factors, for example 10 can be written as 2x5. The natural thing to do would be to iterate over the prime numbers, and if they divided our number, we divide our number by that, and add that factor to the list. We would then stop iterating when we get to a number that is higher than the number ours has become, and the number we are left over with is in fact the largest prime factor.
Now the truth is, with this implementation, we CANNOT write it in one line, since it requires a variable to be set to 600851475143 for us mess with among other factors. However we can actually write a one line program for this, (although it may not fit on one line on this blog):
print(max([factor for factor in range(2, 600851475143) if (600851475143%factor==0 and len([n for n in range(2, factor) if factor%n == 0]) == 0)]))
What it is basically doing is populating a list of numbers that divide 600851475143 evenly, and which cannot be divided evenly by any number other than 1 and itself (i.e. the list of numbers that divide this number between 2 and itself-1 has a length of 0). After that it simply prints out the largest number in that list, which is by definition our "largest prime factor".
The thing is though, this is a HORRIBLE program, and would take a long time to run even on a supercomputer (In fact, trying it myself it generates a memory error before it gets anywhere). So there is a lesson here, SOMETIMES ONE LINE PROGRAMS ARE NOT THE BEST PROGRAMS.
Anyways, implementing the originally stated algorithm, I got the correct answer of 6857 in a much, much faster time, less than a second.
Sunday, February 9, 2014
Frame-Stewart.
So here is something that always shocks me about university assignments:
Why is it that nobody knows how to use Google?
Because if they did, there would be very little issue with the "Tour" part of our latest assignment. The recursive formula we are provided with in the assignment is known as the "Frame-Stewart Algorithm", and in plain english is as follows.
If you have N cheeses:
1. Move n-i cheeses to some peg that isn't the final peg.
2. Using a 3 tower algorithm, move i cheeses to the final peg
3. Using the same procedure as before, move the cheeses from part 1 to the final peg.
That is all there is to it, and there are even extensive papers on the subject complete with various implementations of the program as well as charts showing that it is optimal at least up to 20 cheeses (regardless of the fact that it is an "unproven" conjecture).
So how did I decide to implement it? Well, I wrote two functions, one to solve recursively for 3 stools based on listed indices (mainly so that they could change depending on what the 4 stools one required), then I wrote a program for 4 stools that uses inputted indices and works recursively the same way.
After it spit out a list of tuples, which directly correspond to moves, I then use that list to apply the moves to a model. I considered just applying the moves directly to the model but I felt like it was easier to animate if the list of moves existed BEFORE we applied them, since all we would then need to do is apply, print, apply, print, apply, print etc.
Perhaps for fun I will try to implement it for n-stools.
Why is it that nobody knows how to use Google?
Because if they did, there would be very little issue with the "Tour" part of our latest assignment. The recursive formula we are provided with in the assignment is known as the "Frame-Stewart Algorithm", and in plain english is as follows.
If you have N cheeses:
1. Move n-i cheeses to some peg that isn't the final peg.
2. Using a 3 tower algorithm, move i cheeses to the final peg
3. Using the same procedure as before, move the cheeses from part 1 to the final peg.
That is all there is to it, and there are even extensive papers on the subject complete with various implementations of the program as well as charts showing that it is optimal at least up to 20 cheeses (regardless of the fact that it is an "unproven" conjecture).
So how did I decide to implement it? Well, I wrote two functions, one to solve recursively for 3 stools based on listed indices (mainly so that they could change depending on what the 4 stools one required), then I wrote a program for 4 stools that uses inputted indices and works recursively the same way.
After it spit out a list of tuples, which directly correspond to moves, I then use that list to apply the moves to a model. I considered just applying the moves directly to the model but I felt like it was easier to animate if the list of moves existed BEFORE we applied them, since all we would then need to do is apply, print, apply, print, apply, print etc.
Perhaps for fun I will try to implement it for n-stools.
Monday, February 3, 2014
On the Number of Triangles in the Sierpinski Triangle.

While this was brought up in class, the person sitting beside me brought up an interesting problem: "How many triangles are present in any particular depth of generation?" Which I found very interesting! So here is how we (mostly he) solved it together.
If we think of the triangle as being generated by "Removing" the centre triangle each time, the problem is relatively simple. If we think of the single triangle as generation 0, we have the number of triangles being T_n = 3^n where n is the amount of generations.
The problem gets a bit more complicated when you take the centres into account. In this case we can think of it as 1 when n=0, and then since we are generating but ignoring the centres, we can think of those as the amount of triangles in generation n-1 starting at generation 1, giving us T_n=3^n+T_n-1. However maybe it is possible to get an explicit statement of the equation? Well, let us think about what the equation is for each of the n's and see if we can get a pattern. So:
T_1 = 3^1+3^0
T_2 = 3^2+T_1=3^2+3^1+3^0
T_3 = 3^3+3^2+3^1+3^0...
T_n = sum from 0 to n of 3^n
Can we go further though?
Well:
T_n = 3^0+3^1+...+3^n
3T_n = 3^1+3^2+...+3^(n+1)
3T_n = 3^1+3^2+...+3^(n+1)+3^0-3^0
3T_n = T_n+3^(n+1)-1
2T_n = 3^(n+1)-1
T_n = [3^(n+1)-1]/2
Which gives us an explicit answer that doesn't require knowing T_(n-1) :-)
Sunday, January 26, 2014
C'est un Objet
Speaking as a math student, sometimes in an attempt to precisely describe something professors tend to over-complicate it. Objects in programming are one of those things that is almost a trivially simple concept to explain, but is often obscured by complex language. So to prove that it is really not as complicated as it sounds, I decided to explain it to my 76 year old Grandmother.
Here is the explanation:
Computers are idiots. Sure they can do things fast, but in order to get a computer to do something right, you have to sit down and give it incredibly precise instructions. Look at this FreeCell game you play. It's not like all these things just existed in the computer and a few keystrokes built the game, someone had to build it piece by piece, from telling it which cards can go on top of others, to the exact conditions when you win, and even things like what to do when you are holding the mouse button down and moving a card around. In order for this to not drive the poor programmer crazy, he would use something called an "Object". An object is exactly what it sounds like, it is a computer representation of some "object" that behaves like we expect it to. In the case of your FreeCell game, we can think of the card as an object. What a programmer can do is create a "Card" in the computer which would represent what we know of as a card. He would then tell the computer exactly what to do with the card, from it's value, to how it looks, to how it behaves when you click on it, as well as whether you can stack them on top of each other, and the conditions for winning. Simple attributes like the suit and value of the card would be stored as "variables", and complicated behaviours that the card can engage in are written as what we call "methods", which is just a fancy way of saying "stuff the card does".Sure, that maybe isn't super precise, and being a university you would expect that the professor would teach you a 100% accurate model... however sometimes there is room for a bastardized explanation. Maybe preciseness can come after understanding.
Subscribe to:
Posts (Atom)